More on Teaching an AI to Play ZX Spectrum Games
An update on my adventures in trying to teach an AI to play ZX Spectrum Games.

My last post covered my first steps in teaching an AI to play ZX Spectrum games. I've made quite a bit of progress since then so thought I'd share.
Game Configuration
To train an AI you need to control the game in question; reset it to start training, extract the score, etc. Previously I was doing this in C# code, I've now changed things so everything needed to train a game can be specified in YAML. This will allow other people to write their own YAML files and train their favourite games. There are several parts to the YAML:
Game Details
This section gives some basic details about the game along with a link to get download the game on the internet. I believe the games I'm training are free to distribute, but finding out exact information for the current copyright of 40 year old games isn't straightforward, so I decided to link to files on The Internet Archive instead.
The other important part of the details is the play area. Most games aren't truly full screen, for example the bottom part of the screen in Deathchase shows the score, high score, lives, etc. which isn't needed by the AI.
Data
The data section specifies where in the game important parts of data are located:
data:
- name: lives
type: number_string(1)
location: 0x6987
- name: rng_seed
type: word
location: 0x5CB0
- name: rng_counter
type: word
location: 0x5DCF
- name: score
type: number_string(6)
location: 0x6BCD
...
Each item of data has a location in memory and a data type. Simple types such as byte and word are supported, along with more complex types such as the number_string type shown above. This is needed for Deathchase which stores the score as the ASCII text for the number.
Routines
The routines section specifies where in the game various routines are located:
routines:
- name: main_loop
location: 0x663D
- name: check_keyboard_to_start_game
location: 0x62AE
- name: crash
location: 0x6711
...
These routines can be referenced in other parts of the configuration to control the game.
Actions
Describes the various actions that the AI can take to play the game:
actions:
- none:
- left: 1
- right: 0
- accelerate: 9
- accelerate_left: [accelerate, left]
- accelerate_right: [accelerate, right]
...
Actions can be specified as the key to press, or as a composite of other actions.
Reset
Describes how to reset the game before starting AI training. The reset process is a sequence of operations such as calling routines or pressing keys:
reset:
operations:
- jump: start_new_game
# Carry on through the rest of start_new_game until we reach the keyboard check to actually start the game.
- run_until: check_keyboard_to_start_game
# Press 1 to start the game using the keyboard for input.
- set_keys: 1
- run_until: main_loop
The above starts a game of Deathchase. We jump to the routine to start the game. We then let that progress until the routine to check the keyboard is reached. At that point we press 1 to select keyboard and then continue on until the main game loop is reached.
Stop Conditions and Step Result
When training the AI we perform a step. Each step involves giving the AI the current state of the game and asking it to choose an action. We then progress the emulation for a fixed number of frames and work out a reward for the AI at the end. We also need to specify if training should end, e.g. if our player has been killed or if they have completed the game. This process is controlled by these sections:
step_result:
before: score
after: score
reward: after - before
stop_conditions:
- routine: crash
result: loss
For a step we record a value before the step and a second after. We are just using single data values here, but full expressions are supported. The reward in this case is just calculated as the increase in score.
In Deathchase the game goes for ever so there is no win condition, but there is a lose condition, when we crash into a tree.
Randomize
Computers are deterministic, so if we start the game the same way every time we can expect it to proceed the same way too. This is not ideal for AI training as we want it to explore different outcomes. For games like Deathchase that use randomness, the randomize section allows us to update the data that controls that before starting an episode:
randomize:
- set: rng_seed
value: random()
- set: rng_counter
value: random()
AI Configuration
All the above is specific to the game and could be used without an AI if you just wanted to inspect the game. And I've added a window to my emulator to do just that:
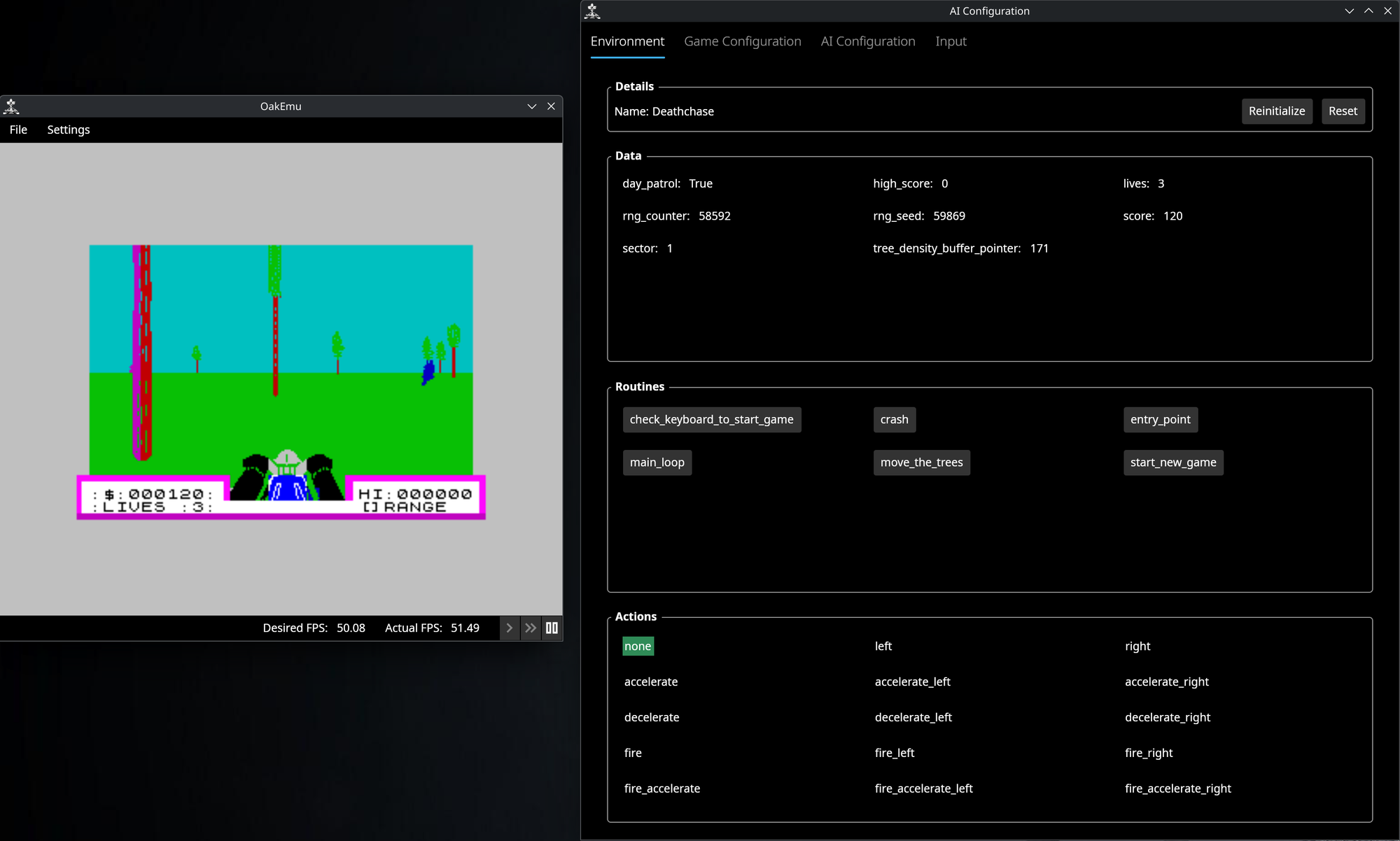
I've therefore also got a separate AI file that controls options just for training:
observation:
frame_skip: 4
area: play_area
output:
type: single
size: (128, 128)
frames: 6
The above specified that we should skip some frames, just running the AI every 4th frame. The area to capture is the play area we specified in the game configuration, but other areas could be used. The output to send to the AI uses single precision values for the image data. The area is scaled to 128x128 and we keep a stack of 6 frames to give to the AI. We need to send multiple frames to the AI or it will not have any concept of time.
Bug Fixes
I fixed various bugs affecting the training. Most minor but a few quite major ones!
Invalid Score Crashes
Evaluating the rewards at the end of the step would occasionally crash. Deathchase stores the score as an ASCII string to avoid having to convert back and forth to text when displaying the score. The crash would occur due to the score not being a valid number but being something like 12345\, i.e. ending in a backslash. This one took me a long time to track down!
After picking apart the Deathchase code for the score update routine, I managed to work out what was happening. The score is updated by incrementing the right most digit's ASCII value. So 0 goes to 1, 5 goes to 6 and 9 will go to \, as that is the ASCII character following 9. The routine then checks if \ has been produced; if so, it resets it to 0 and increments the next digit to the left, i.e. arithmetic carry.
The bug was triggering when I was attempting to read the score part-way through the routine. Which would happen occasionally if the end of the step happened to occur during that routine. To fix this I added the concept of critical sections:
critical_sections:
- name: update_score
start: 0x6991
end: 0x699B
This states that if the end of the step occurs in the range 0x6991 to 0x699B, which is the scoring routine, we should continue with the emulation until the routine is finished. Then we can safely read the score.
Corrupted Images
The AI models I'm training all start with convolution layers. These layers divided the images up into squares and then apply a filter to each square. These filters help the AI identify features in the image such as edges or small objects.
All well and good until you mix up the coordinates in your stack of frames and confuse height, width and frame number. Instead of feeding in, say 6 128x128 frames, I was giving the AI 128 128x6 frames...
I didn't spot this for a long time because the AI still trained quite well with the incorrect frames. The PPO algorithm was consuming the corrupt images quite happily and giving me an agent that would still average a score in the thousands! I only noticed the mistake when I started writing the code to display the intermediate layers in the UI so you can 'see' what the AI 'sees'.
Training Improvements
Start Conditions
My initial training attempts of Deathchase were fairly slow due to how the game works. After killing two enemies the game flips from day mode to night mode where the background is black instead of cyan. After killing the two enemies at night, it flips back to day mode but with more trees. As I was starting the game afresh each training episode it meant the AI would have to play for a period of time before seeing night mode or the harder difficulties. To speed this up, I start the game randomly on either day or night, and at a random skill level.
Starting at Night
Whether the game is in day or night mode is controlled by bit 0 of the value at 0x5DD3 in memory. The full value used is 10101010 in binary; when the game wants to switch between day and night, it uses the RRCA instruction to rotate the bits in a circular fashion. For night mode this therefore becomes 01010101. To override day or night we simply modify the code that sets the initial value. As a slight peculiarity, the game initialization code sets it to the night mode value and then flips it during initialization as part of redrawing, so we set to the opposite value. The actual code is a bit more complicated and in fact sets the value twice, but the trick described here is enough for my purposes.
Changing the Difficulty
Each level in the game has more trees than the last. There are buffers that describe the density of trees to use. On top of this, there is a further table that points to the buffers to use. When moving to the next level, the next pointer in the table is used, and resetting the game moves back to the first pointer.
Luckily for us there are four extra tree density buffers defined, along with four entries in the table, that are never used by the game. This means to increase the difficulty we can override the starting pointer to be any of the first four entries.
Full Configuration
The full configuration to include these options is:
reset:
parameters:
- name: start_in_night_patrol
type: boolean
default: false
- name: difficulty
type: byte(0, 3)
default: 0
operations:
- set: tree_density_buffer_pointer
value: 0xAB + difficulty
- jump: start_new_game
# Just before calling move_the_trees, the day_patrol flag has been reset. The flag is flipped later on in the start routine when
# switch_sector is called. This means it has been set to the opposite of the starting value. We've therefore defined our parameter
# the opposite way around.
- run_until: move_the_trees
- set: day_patrol
value: start_in_night_patrol
# Carry on through the rest of start_new_game until we reach the keyboard check to actually start the game.
- run_until: check_keyboard_to_start_game
# Press 1 to start the game using the keyboard for input
- set_keys: 1
- run_until: main_loop
The reset section can be parameterised, and these parameters can be used in the operations. Our AI training configuration can then override the defaults:
training:
reset:
arguments:
- name: start_in_night_patrol
value: random()
- name: difficulty
value: random()
These tweaks enable the training to proceed much faster.
Image Output
The ZX Spectrum has 8 colours, with normal or bright versions; black and bright black display the same, however. The image input to the AI uses a number from 0 to 1 for each pixel. Initially I was just spreading the 16 colours out evenly over the range. This meant that the AI wasn't 'seeing' the image as a human would.
To improve this, I added proper greyscale conversion. As it turns out this is way more complicated than I thought... It's not just a case of averaging the red, green and blue components of a colour as this would make, for example, red, green and blue all the same grey. Instead, we need to take into account how sensitive the eye is to red, green and blue. There are a number of standards for this that have different formulae. I've implemented two:
- Rec 601, used for SD video formats like NTSC and PAL: 0.299R + 0.587G + 0.114B
- Rec 709, used for HD video formats like 720p, 1080i and 1080p: 0.2126R + 0.7152G + 0.0722B
Reward Improvements
Reward Tweaks
Deathchase doesn't have a score penalty for losing a life. The training episode just ends. This means that the AI could move toward strategies where avoiding a tree wasn't that important. To accommodate this I added support for referencing the win/loss state when calculating rewards:
step_result:
before: score
after: score
# Small penalty for losing a life to encourage the agent to keep playing.
reward: "after - before - (loss ? 10 : 0)"
Reward Normalization
Some AI training algorithms prefer a reward range of -1 to 1; training is more stable with such a range. To support this, I have added YAML options to normalize rewards:
step_result:
...
normalize:
# 1000 points for shooting a helicopter/tank. Normalize to that, evenly around 0. Will ignore a slight increase from the step when scoring 1000.
expected_range: [-1000, 1000]
desired_range: [-1, 1]
# Will clip out the small scoring increase from the step when scoring 1000.
clip: [-1, 1]
We define the expected range of scores we expect from a single step, and then normalize that to the desired range. We also clip the result to make sure we don't go outside the desired range.
Different Algorithms
The PPO algorithm has been doing fairly well for me, but I could never get it to settle on a superhuman level of performance. It would either settle on just avoiding trees but not scoring heavily, or a mid-level of score and game length.
Switching to Rainbow DQN has improved matters greatly. This is the basic DQN algorithm used in the original Atari paper with various extensions to improve training. This has given me an AI that can score in the tens of thousands. As well as avoiding trees, it steers towards enemies to aim shots towards them, rather than just hitting them randomly as PPO did.
This has given me an AI that is far better than the game I ever was:
Rainbow DQN trained AI playing Deathchase
Next Steps
Still a lot to do. The main one is to move my training code to another AI framework. I've been using Ray so far, but I've just hit too many bugs with it:
* After getting my new PC, I was unable to restore training from checkpoints. Turns out this is a [known issue](https://github.com/ray-project/ray/issues/51560; fortunately, there is a workaround.
* PPO would use a roughly constant amount of GPU memory whilst training, but occasionally it would request a much larger amount, causing the GPU to run out of memory and training to stop.
* I cannot use a decent size replay buffer with Rainbow DQN due to another bug.
* Rainbow DQN often does not restore correctly from checkpoints. It does work and outputs to the console, but the model does not update any further.
* Various other issues where parameters are not correct resulting in a cryptic error.
It's a shame because it's clearly a powerful framework and makes a lot of things simple but just doesn't have the stability or polish I'd like. I just cannot achieve superhuman AI levels with the bugs in it currently.
After switching frameworks my next steps are:
- Finish the UI for the emulator.
- Add support for running an AI in the emulator. At a challenging part in your favourite game? Hit the AI button and let it take over!
- Add support for displaying output from the various layers in an AI model.
- Tidy up the code and get it into a state where it can be released.
I still haven't released any of the code or the emulator. I did at least release a (suite of tests)[https://github.com/MrKWatkins/EmulatorTestSuites]] people can use when writing their own Z80 emulators. But still to release:
- OakAsm, a general framework for assembling and disassembling Z80 code.
- OakEmu, the ZX Spectrum emulator itself.
- OakCpu, a cycle accurate Z80 emulator I accidentally wrote.
- OakEmu-Python, Python wrappers for OakEmu.
- OakEmu-AI, Python code that lets you run the ZX Spectrum in a Gymnasium environment, along with all my example training code.
I'll try and give more frequent updates too, but I've said that many times before...
Oh and of course teach it to play Manic Miner.